

高频做市商的“成交困境”,以及逆向选择的那层真相
成交越多越亏:
做过做市的人大多都有过同一种经历:
你把阈值放低一点、把挂单贴近一点、把撤单宽松一点,成交立刻变多;但是如果你还贪心,想继续增加交易量,就会发现随着交易量增加,平均每笔收益变差,越亏越多,越做越像在给市场交“隐形税”。
这和对手方的Taker手续费、Tick精度占比密切相关,也就是对手盘的手续费越高,Tick精度越大,趋势发动的成本就会越高,你要赚的Spread就要越大。
这是一种结构性的两难:Fill Probability 上去了,Post-Fill Return 往往更差。
最直觉、也最常见的解决办法当然是“提高成交难度”:挂得更远、价差更大、撤得更快。问题在于这等于默认接受了“要赚钱就得少成交”,把做市变成一种保守的被动生意。
除了“提高成交难度”之外,还有没有更好的做法?
有。但前提是,你得需要认识到这件事的本质不是“成交多少”,而是你在跟谁成交——也就是做市里绕不开的四个字:逆向选择。
1. 逆向选择:老生常谈,但永远是重中之重
逆向选择说得直白一点:在信息不对称的市场里,吃你单的人往往更“有消息”、更“快”、更“确定”。你一成交,价格反而顺着对手方向继续走,你吃到的那点 spread 很快就被更差的 markout 吃回去,甚至倒贴,你成了“接盘侠”。
也正因为如此,大部分做市策略无论显式还是隐式,本质都在做同一件事:尽量少吃有毒成交。
在我们的尝试下,在某交易所,用RFI挂单(新出的一种订单形式,只和个人玩家成交,不与Api订单成交),不需要增加任何alpha,无脑挂单就能稳定赚钱
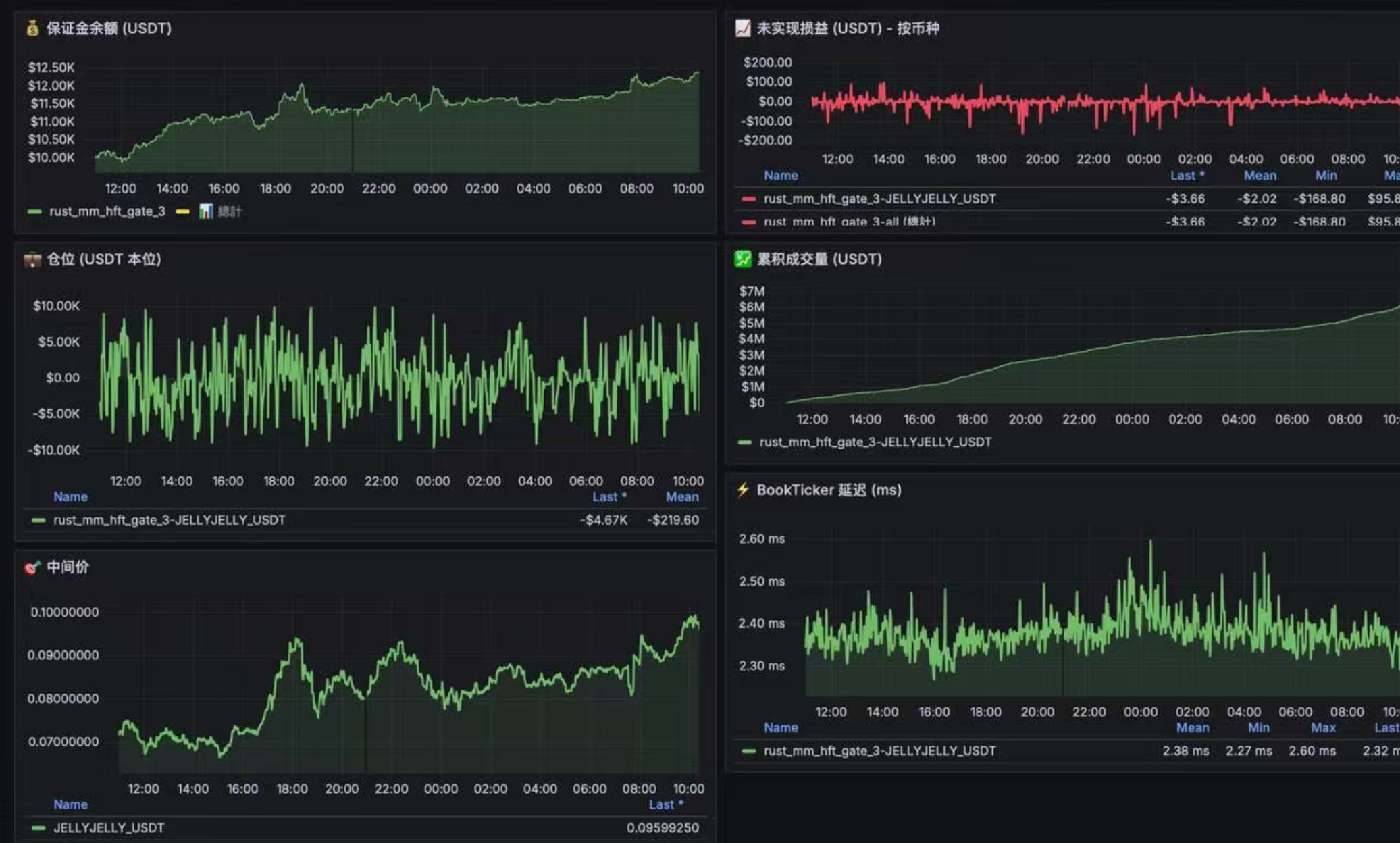
为什么会这样?
- API订单,都是专业玩家,有编程的基础,自带Alpha,大部分都是有毒订单
- 个人玩家,二八定律,20%的人赚钱,80%亏钱,说白了就是韭菜
2. “成交困境”不是感觉:在真实做市里,它可以被量化
一篇很有代表性的实盘工作《The Market Maker’s Dilemma: Navigating the Fill Probability vs. Post-Fill Returns Trade-Off》直接把这件事摊开讲:作者在币安 BTC 永续上做了真实的做市实验,用最朴素的 maker 基线去量化这个 trade-off。
他们的做法很简单:
- 先当一周“傻瓜做市商”:永远挂在最优 bid/ask,有仓位就平掉。
- 用本侧队列量、对侧队列量和盘口不平衡度等信息,拟合一个经验成交概率函数

- 然后在相同“队列条件”下统计:如果这类单被吃掉,接下来几秒钟的平均收益是多少。
结论非常干脆:成交越容易的区域,成交概率更高,但成交后的平均收益明显偏负;成交越困难的区域未必很好赚,但至少离 0 更近。
也就是说:
- 高成交率天然绑定更强的逆向选择
- 想“多成交”,本质就是往更“有毒”的区域走
- 真要盈利,你关注的应当是“哪些成交值得吃”,而不是“怎么让更多成交发生”
这就是做市里最常见的 KPI 陷阱:把成交当 KPI,你会被市场奖励“成交”;但市场不会奖励你“赚钱”。
3. 关键一手:在“高成交概率区域”里识别好坏成交
到这里,很多人会下意识走向一个结论:那就把单挂远点、少成交。
但这篇工作的真正价值在于,它告诉你:不是只能二选一。你可以把“多成交 vs 多赚钱”的矛盾,变成一个更可控的问题——
只在“高成交概率区域”里,学习区分“好成交 vs 有毒成交”。
它的核心是“先条件化,再分类”:
-
用 $p_{\mathrm{fill}}$ 先缩小关注范围
用上一步得到的 $p_{\mathrm{fill}}$,在每一笔订单提交时算一个估计成交概率:
$\hat{p}{\mathrm{fill}} = p{\mathrm{fill}}(q{\mathrm{near}}, q{\mathrm{opp}}, I)$
然后只保留那些满足 $\hat{p}_{\mathrm{fill}} \ge 0.8$ 的订单,得到一个“高成交概率子集”。
这些单的含义是:从队列结构看,它们八成会被吃掉。 -
在这个子集上重新定义“好 / 坏成交”
对每一笔属于高成交概率子集的订单,看真实路径:
- 若最终没成:记为 0;
- 若成了,找到成交完成后,midprice 第一次变动的时刻,计算收益:
- 若对做市商不利(价格继续沿对手方向走),记为 0;
- 若对做市商有利(价格反向走),记为 1(reversal)。
这样,标签就不再是“会不会涨跌”,而是在一个本来就高成交概率、风险较大的状态下,这笔真实发生的成交,是“好成交”(1)还是“有毒成交 / 一般成交”(0)。
这一步剔除了大量“本来就成不了”的噪声样本,把模型训练任务聚焦在“如何在必成区域内识别好坏成交”这一件事上,更贴近做市的实际决策。
4. 模型和策略:不需要全能大脑,只要一层“过滤门”
在有了「高成交概率子集 + 好/坏标签」之后,作者才开始建模,这里他们也刻意保持简单:
- 特征:多时间尺度上的价格振幅、短期收益结构(自相关等)、成交频率与方向,外加顶档挂单量、深度分布、top-of-book 存活时间等标准 LOB 信息。
- 模型:Logistic 回归(方便看系数)和 Random Forest(做非线性对照和重要性分析)。
真正关键的是策略层怎么用。它不是推翻原有做市框架,而是在原框架上加一道“门”:
- 仍然沿用最简单的做市骨架:挂在最优 bid/ask、仓位 -1/0/+1、成一边补另一边。
-
每次准备挂单时:
- 先看 $\hat{p}_{\mathrm{fill}}$ 是否在高成交概率区
- 若是,再看 $P(\mathrm{rev} \mid x)$ 是否高于阈值
- 只有满足才允许挂单,否则就拒绝这笔潜在成交
一句话概括这层过滤器的角色:
它替你多问一句——“这笔几乎肯定会成的挂单,值不值得让我成交?”
效果也符合直觉:阈值提高后,每日成交次数减少,但单笔往返收益从负转正,整体 Sharpe 改善。
这不是“少做单就赚钱”,而是“少做坏单就赚钱”。
5. 回到开头的问题:除了提高成交难度,还能怎么做得更好?
“提高成交难度”本质是被动防守:把自己从危险区域撤出来。
而上述思路提供了一种更主动的路径:在危险区域里做精细化筛选——不靠“整体变保守”,而靠“有选择地拒绝”。
当然,过滤层不是唯一答案。把视野放宽一点,规避有毒订单的手段本来就是一套组合拳:配合预测偏移报价、缩短挂单有效期或在异常时及时撤单、在高风险时期收缩敞口、精挑细选下单时机……论文只是其中一种实现方式。
更现实的做法往往是叠加使用:
- 价差 / quote skew:决定你愿意在什么价格上见对手
- 时间与撤单规则:决定你暴露多久(行情延迟更是危险信号)
- 库存与下单量:决定你一次承担多大风险
- 过滤规则与模型:在关键场景下给你一票否决权
把它们串起来,其实就是一句最朴素的职业经验:
先认清成交背后的逆向选择,再学会对一部分成交说“不”。
结语:做市不是和数据做生意,而是和对手玩无限游戏
逆向选择是做市商的入门考题,也是所有老练交易者需要用整个职业生涯反复解答的终极命题。
因为你面对的不是固定规律,而是同样聪明、同样贪婪、同样会进化的对手。
所以,做市这门生意真正的“经验感”,从来不是“怎么成交更多”,而是:
当市场兴奋地把成交送到你面前时,你能不能冷静地分辨——
这到底是一笔利润,还是一口毒。